TL;DRSemantic sampling of query points for tracking with explicit motion modeling improves few-shot action recognition.
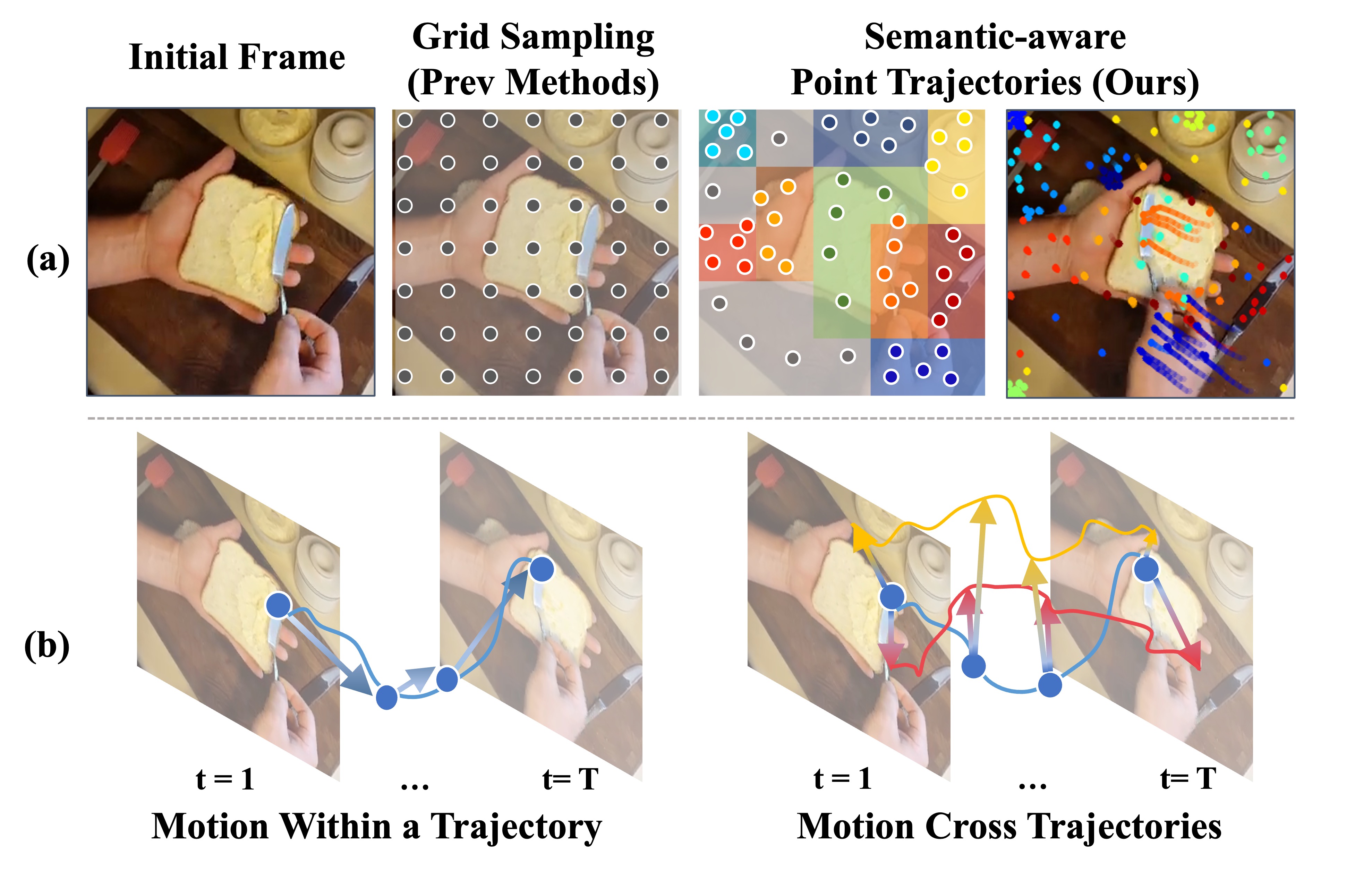
While recent advances in point tracking have been shown to improve few-shot action recognition, two fundamental challenges persist. (a) How can we develop an effective sampling strategy of query points for tracking that balances coverage and efficiency? Our semantic-aware points adapts better to object scale and semantic relevance while existing methods w/ grid sampling missed small objects w/ important motion (e.g., knife). (b) How can we explicitly model and utilize the motion patterns captured in point trajectories? We explicitly model relational motions within a trajectory and across trajectories.

Visualization of action trajectory similarities across four classes, where our semantic-based sampling enables object-focused trajectories. Each quadrant demonstrates intra-class motion consistency while maintaining inter-class discriminative features.












More qualitative results of our semantic-aware point trajectories. For each action class, we randomly selected videos and overlaid them with our extracted semantic-aware point trajectories. Our method successfully focuses on action-relevant objects, even when they are small. We observe that trajectories from the same action class follow very similar motion patterns.
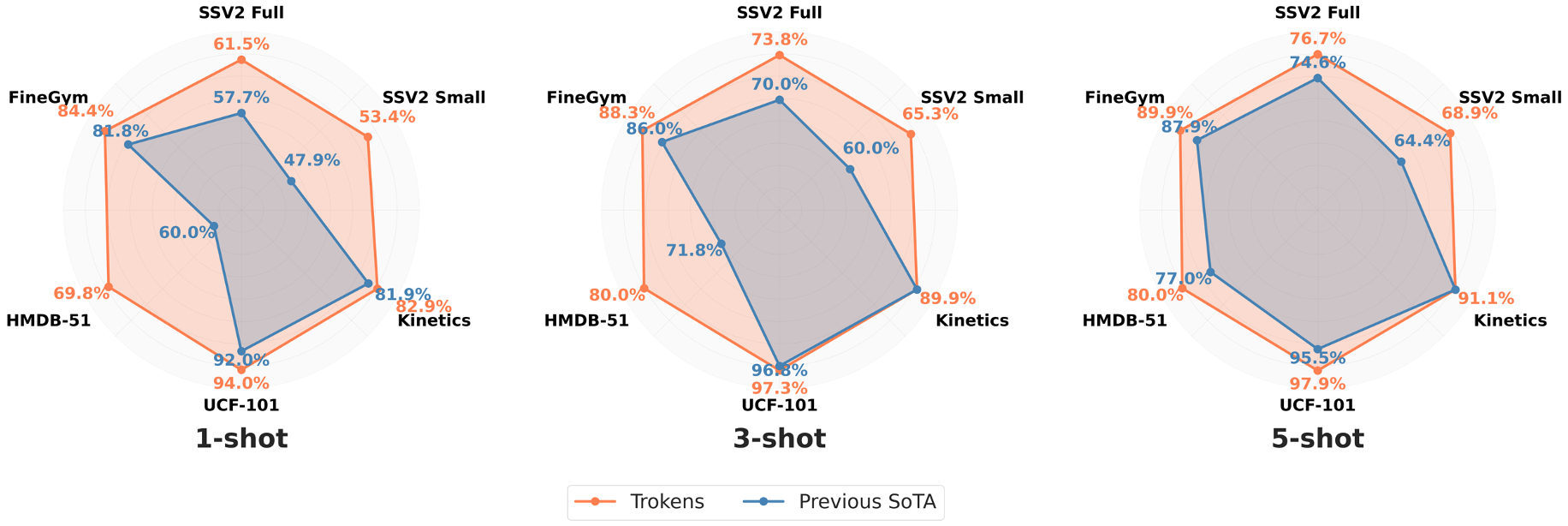
Trokens achieves state-of-the-art few-shot action recognition performance across 1, 3, and 5-shot settings on SSV2, Kinetics, UCF-101, HMDB-51, and FineGym datasets, outperforming all contemporary methods.
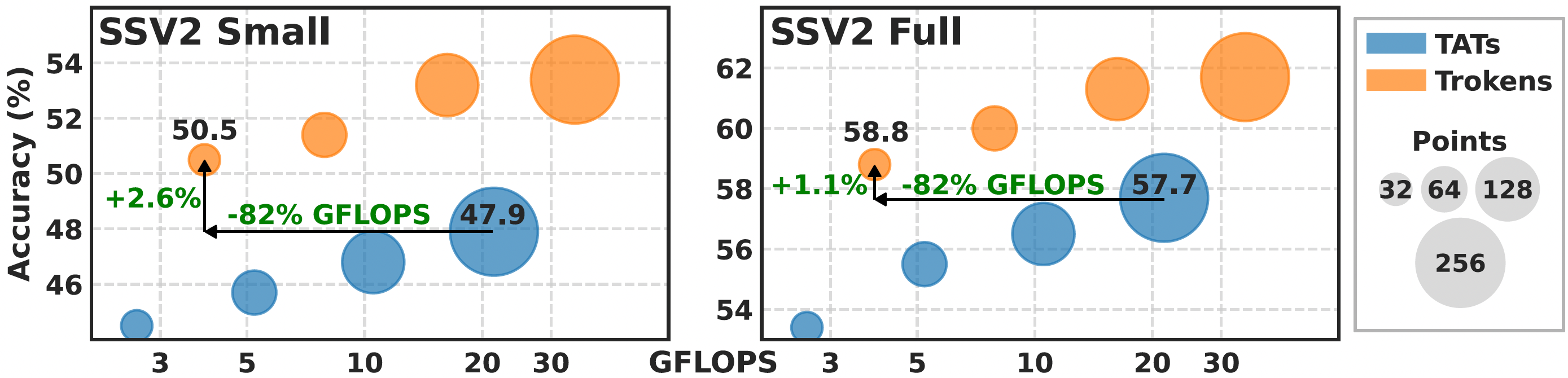
Trokens offsets the computational cost of clustering by efficiently selecting points that achieve higher performance with fewer tracking points. For both SSV2 Small and SSV2 Full, Trokens with just 32 points surpasses TATs (uniform sampling) with 256 points, while using 82% fewer inference-time FLOPs overall.
@inproceedings{kumar2025trokens,
title={Trokens: Semantic-Aware Relational Trajectory Tokens for Few-Shot Action Recognition},
author={Kumar, Pulkit and Huang, Shuaiyi and Walmer, Matthew and Rambhatla, Sai Saketh and Shrivastava, Abhinav},
booktitle={International Conference on Computer Vision},
year={2025}
}
@inproceedings{kumar2024trajectory,
title={Trajectory-aligned Space-time Tokens for Few-shot Action Recognition},
author={Kumar, Pulkit and Padmanabhan, Namitha and Luo, Luke and Rambhatla, Sai Saketh and Shrivastava, Abhinav},
booktitle={European Conference on Computer Vision},
pages={474--493},
year={2024},
organization={Springer}
}